
In the rapidly changing ecosystem of data platforms, selecting a data warehouse technology is vital to your organization’s ability to make data-driven decisions, create all new products, and stay competitive. The selection of warehouse technology also significantly influences various factors, including cloud costs, scalability, and the operational burden on your staff. Among the myriad of options in this arena of data warehouses and platforms, are Amazon Redshift and Databricks, each with its unique strengths and capabilities. As businesses strive for more efficient, scalable, and flexible data analytics solutions, the question often arises: which platform holds the key to unlocking the full potential of their data?
The Bentley Ave Data Labs team has extensive experience with both Redshift and Databricks platforms, and with this article, we’d like to delve into the nuances between the two. We will explore the advantages and disadvantages, as well as the fundamental difference that defines a “data warehouse” versus a lakehouse platform. In particular, we focus on showing why we are confident of the advantages Databricks has against Redshift and why organizations should consider a strategic migration to position their business for success with analytics and AI.
Understanding Redshift and Databricks
Amazon Redshift is a flagship data warehouse product from Amazon Web Services (AWS), which many organizations have relied on for more than 10 years for storage and computing. Redshift has been a popular option, mainly due to its ability to handle large amounts of data thanks to its design based on massively parallel processing (MPP); many users found this compelling coming from relational database backgrounds such as MySQL, as it enables querying and ETL of large datasets with relatively low speeds. This especially works well when exercised as a weapon for data analytics, powering ETL such as aggregations for reports and data products for hundreds of millions of rows, terabytes, and more of data, that was previously impossible with RDMS due to limited, expensive, compute and parallelism.
Databricks reinvents the approach to data analytics and AI with its Lakehouse architecture. In Databricks, storage and compute are decoupled and leverage open source Apache Spark as the backbone of distributed computing and Delta Lake for an ACID-compliant optimized engine on top of scalable cloud object storage like S3 and Azure Data Lake Storage (ADLS). Collectively, these design choices make the Lakehouse platform powerful because everything is highly scalable without requiring expensive storage built into the same deployment (we all love how cheap S3 is).
Challenges with Redshift
Let’s jump right into some of the pain points users face with Redshift; if you use Redshift currently, see if these challenges resonate with you. First, there are several limitations that may restrict developer and administrative flexibility on Redshift:
- Limited to SQL language
- Some support for controlling partitioning through “distribution styles”
- Limited and siloed controls for data governance
The first may be a nonissue for teams primarily composed of data analysts and DBA backgrounds, but SQL has plenty of facets where it falls short, such as lack of modularization, version control, and stored procedure maintainability, to name a few. Second, distribution styles in Redshift allow you to ask the warehouse to disperse your data in styles such as DISTKEY, where you define a key column that controls partitioning, and EVEN, where the warehouse spreads the data evenly in a round-robin fashion across its nodes. These options work for many cases, but it would be nice to have more control over your actual storage layer – it simply isn’t a concept that aligns with data warehouses that couple storage into their hosting. Similarly, security controls and ACLs must be copied and managed independently in Redshift, as well as any IAM roles leveraged during a session on Redshift (e.g., such as during COPY and UNLOAD of data), making data governance difficult to enforce or maintain across the enterprise.
Next, many users find Redshift’s choices of Dense Storage vs. Dense Compute for the size of the cluster to be a cost and scalability bottleneck. When creating your Redshift data warehouse, you must choose whether the cluster will be Dense Compute or Dense Storage. Dense Compute is great for high-performance computing, such as analytics and CPU-intensive calculations, but is much more expensive, especially for workloads that require more storage capacity; Dense Storage is inversely related to compute, having cheaper cost for large storage capacity but being much more limited on compute performance. This pits data practitioners against the tradeoff of compute vs. storage without much middle ground. If you need HPC and large storage capacity, prepare to break out the checkbook!
Lastly, and perhaps most importantly, a key challenge with Redshift and all data warehouses is that, by nature, these warehouses require copying of data in and out of their hosted storage. Redshift uses the SQL commands COPY and UNLOAD to load and export large datasets. Over time, this results in teams having several disparate and out-of-sync copies of data across both cloud storage like S3 and Redshift tables. As mentioned before, data silos like this are a data governance nightmare due to the extreme ease of leaking data or ACLs that protect access to it. If nothing else, wouldn’t it be nice to simply query the data without constantly copying it into a server first? Furthermore, it’s vital to keep AWS vendor lock-in in mind as your backend applications and BI tools become more dependent on data copy and movement to Redshift and its arsenal of stored procedures.
The Databricks Advantage
- Highlight the strengths and advantages of Databricks over Redshift
- Unified platform without the necessary vendor lock-in
- Scalability, performance, and flexibility
- Decouples storage from compute for best scalability and cost efficiency
- Data is not copied, so it is more cost-effective and secure
- Integration capabilities and support for various data sources
- Supports Python, SQL, and Scala languages
- Built-in support for ingesting files from cloud storages such as S3, databases (including Redshift), and streams such as Kafka and Kinesis
- Supports both batch and streaming workloads
It’s no secret that all things point to Databricks outshining Redshift, and ultimately this really comes down to it being a comprehensive platform for data and AI, as well as the architecture decoupling of compute vs. storage. Benefits yielded, such as the unified interface, scalability, performance, and costs, are all attributed to those architecture decisions Databricks has chosen to root itself in, which comes as no surprise considering these are the same brilliant minds that created Apache Spark.
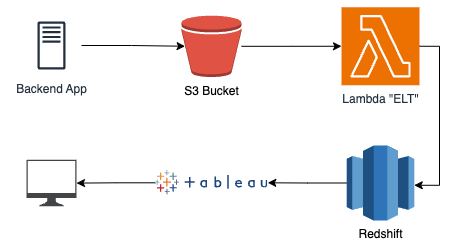
Let’s see an example of this stackup. Given a use case of clickstream data that needs to be aggregated into critical business reports, we may create a solution leveraging Redshift like so – but our BI reports require additional tooling 😞 so let’s add in Tableau as well.
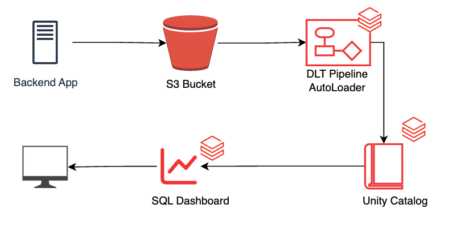
Whereas a Databricks solution to the same use case is much more unified thanks to the data intelligence platform’s broad toolset. With Databricks, we can automatically ingest the files into an optimized Lakehouse using a Delta Live Tables (DLT) pipeline and Databricks AutoLoader. This optimizes unstructured and structured data with the open Delta Lake format and can take advantage of many features such as Liquid Clustering, Deletion Vectors, partitioning and z-ordering, and Predictive I/O, to name a few.
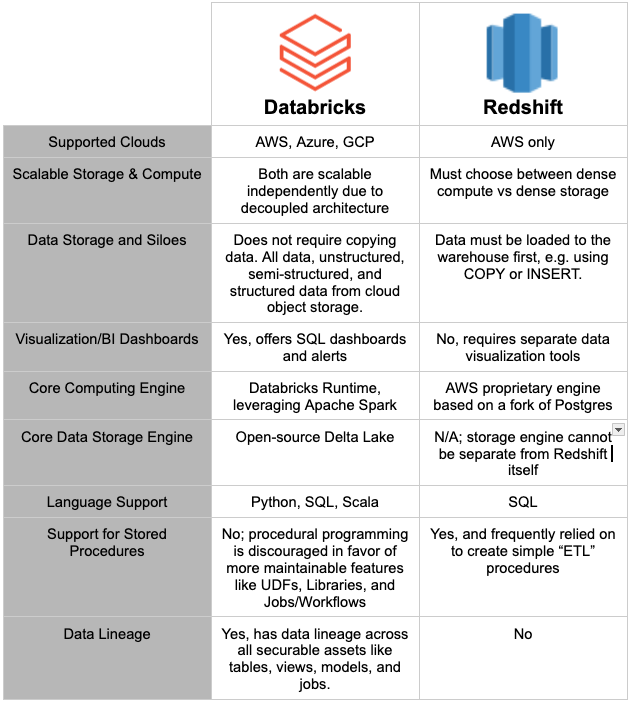
Feature Comparison: Databricks vs. Redshift
Migrating from Redshift to Databricks: A Strategic Leap
Another great aspect of Databricks’ platform our clients love is its openness to integrating with data warehouses and other vendors; if you prefer to take incremental steps toward migration, you can usually ease into it with a lift-and-shift strategy. For example, in the previous solution, we could have kept Tableau instead of switching to Databricks SQL Dashboards. To do this, we would use the Databricks SQL warehouse support for Tableau–and Databricks supports all the other most popular BI tools as well (e.g., PowerBI).
If you’re interested in alternatives to Redshift or considering a migration, what is the next logical step? No sugarcoating here, migration of a large heavily relied-on Redshift data warehouse can be very tedious and challenging to do effectively. Here are a few of the most common challenges customers can expect to encounter when trying to disembark Redshift:
- Mapping table schemas and data types from one engine to another isn’t always “apples to apples” or can lead to equally bad performance when not converting up to best practice engine-specific designs.
- Transferring all that data! At some point, data has to be moved, which can be expensive and time-consuming, especially if it requires downtime from your apps.
- Stored procedures get messy, hard to find, and are usually undocumented, and porting them may sometimes mean a User Defined Function (UDF) or something as complex as an actual ETL job.
In our experience, teams of 10-20 engineers that migrate from Redshift, with between 10-200 tables, take, on average, about three months to complete the migration effort. This varies based on requirements, downstream processes, and physical data sizes but is generally a several-month process. This may sound daunting when you start trying to explain the ROI to your executive leadership but fear not…
Bentley Ave Data Labs is here to help! Reach out to our team of Databricks experts for scoping and help with your Redshift migration and other data needs today.
Migrating from Redshift to Databricks: A Strategic Leap
Another great aspect of Databricks’ platform our clients love is its openness to integrating with data warehouses and other vendors; if you prefer to take incremental steps toward migration, you can usually ease into it with a lift-and-shift strategy. For example, in the previous solution, we could have kept Tableau instead of switching to Databricks SQL Dashboards. To do this, we would use the Databricks SQL warehouse support for Tableau–and Databricks supports all the other most popular BI tools as well (e.g., PowerBI).
If you’re interested in alternatives to Redshift or considering a migration, what is the next logical step? No sugarcoating here, migration of a large heavily relied-on Redshift data warehouse can be very tedious and challenging to do effectively. Here are a few of the most common challenges customers can expect to encounter when trying to disembark Redshift:
- Mapping table schemas and data types from one engine to another isn’t always “apples to apples” or can lead to equally bad performance when not converting up to best practice engine-specific designs.
- Transferring all that data! At some point, data has to be moved, which can be expensive and time-consuming, especially if it requires downtime from your apps.
- Stored procedures get messy, hard to find, and are usually undocumented, and porting them may sometimes mean a User Defined Function (UDF) or something as complex as an actual ETL job.
In our experience, teams of 10-20 engineers that migrate from Redshift, with between 10-200 tables, take, on average, about three months to complete the migration effort. This varies based on requirements, downstream processes, and physical data sizes but is generally a several-month process. This may sound daunting when you start trying to explain the ROI to your executive leadership but fear not…
Bentley Ave Data Labs is here to help! Reach out to our team of Databricks experts for scoping and help with your Redshift migration and other data needs today.
Cost Considerations and ROI
Migrating from Redshift to Databricks isn’t just about feature enrichment and scalability, it also makes sense when considering the costs and how setting your data team up for success can yield massive returns on investment. Here are several factors we encourage clients to consider when choosing a data platform:
1. Infrastructure Costs:
- Databricks offers both classic and serverless compute resources, eliminating overhead costs such as managing and provisioning infrastructure, and scales rapidly. This also enables economies of scale such as making elusive GPUs more accessible to customers.
- Less data duplication = less wasted storage = lower storage costs
- Databricks optimizations such as Photon, Predictive I/O, and Delta caching can reduce total cost of ownership (TCO) by up to 80% and increase workload speeds by up to 12x.
2. Performance Improvements:
- Founded by the same masterminds that gave us Apache Spark, Databricks’ runtime is superior in distributed computing performance.
- Again…Databricks optimizations such as Photon, Liquid Clustering, Predictive I/O, and Delta caching can reduce total cost of ownership (TCO) by up to 80% and increase workload speeds by up to 12x.
3. Flexibility and Scalability:
- The ability to scale resources both vertically and horizontally gives flexibility resulting in reduced costs and better overall resource utilization.
- Lakehouse is flexible to all types of data: structured and unstructured, and is flexible for both analytical and AI/ML use cases.
- The Databricks platform uses a unified experience for all practitioners: data engineering, data science, and data analytics, in a collaborative environment.
4. Training and Skill Set:
- Databricks’ unified interface is easy to learn and get started, no matter if it comes from a SQL-only background or a low-level engineering background, and from a UI-based workflow or an API and infrastructure-as-code controlled process.
- Regular training is available through Databricks Academy, free webinars, and official certifications.
- A low learning curve and simplified ease of use reduce your operational overhead; though if you need help preparing staff and understanding best practices, give us a shout!
5. Integration Capabilities:
- Reduced need to bolt on several additional tools thanks to Databricks’ wide range of supported integrations
- Enables lift-and-shift migration strategies with reduced risks and costs
Conclusion
To recap, if your organization needs data warehousing capabilities for a few specific use cases, Redshift may be sufficient and make sense for teams heavily bought into the AWS stack. Alternatively, organizations looking to expand their use cases to be more data and AI-driven, with less vendor lock-in and more flexibility should consider the comprehensive data intelligence platform, Databricks. We encourage data practitioners to try these out yourself. The decision to migrate off Redshift to Databricks is not light, but hopefully this has compelled you to start strategizing based on your unique use cases and how your business wants to transform its data intelligence journey.
Click here to learn more about how we can help modernize your organization’s data stack

